CPU优化技术系列之NEON开发设计实现方案
随着移动设备和嵌入式系统对高性能计算需求的不断增长,ARM架构下的NEON技术已成为提升CPU性能的关键手段。NEON作为ARM的高级SIMD(单指令多数据)扩展指令集,能够显著加速多媒体处理、信号处理、计算机视觉等数据密集型任务。本文将系统性地介绍NEON技术的开发设计方案及实现路径,为相关技术服务提供参考。
一、NEON技术概述
NEON是ARM Cortex-A系列处理器中的并行处理技术,支持同时处理多个数据元素,适用于向量运算。其128位宽寄存器可同时操作多个8位、16位、32位或64位数据,适用于图像处理、音频编解码、机器学习推理等场景。通过合理利用NEON,开发者可在不增加硬件成本的前提下,实现数倍的性能提升。
二、NEON开发设计流程
- 需求分析:明确应用场景的性能瓶颈,例如图像滤波、矩阵乘法或FFT运算。识别可并行化的数据操作,评估NEON的适用性。
- 算法优化:将标量算法转化为向量化形式。设计数据布局以匹配NEON的加载/存储模式,避免非对齐内存访问。常用技巧包括循环展开、数据重排和减少分支预测。
- 指令选择:根据数据类型(如int8、float32)选择适当的NEON指令。ARM提供内在函数(intrinsics)和汇编两种编程方式,内在函数更易于维护,而汇编可最大化性能。
- 性能调优:通过分析工具(如ARM DS-5或Linux perf)检测缓存命中率和指令吞吐量,优化内存访问模式,减少流水线停顿。
三、实现方案与示例
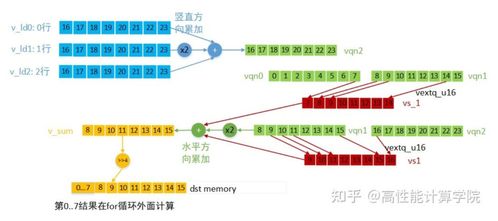
以图像灰度化为例,传统逐像素处理效率较低,而NEON可并行处理多个像素。以下为使用ARM NEON内在函数的简化代码:`c
#include
void grayscaleneon(uint8t rgb, uint8_t gray, int len) {
int i;
for (i = 0; i < len; i += 16) {
uint8x16x3t rgbvec = vld3qu8(rgb + i * 3); // 加载16个像素的RGB数据
uint16x8t rlo = vmovlu8(vgetlowu8(rgbvec.val[0])); // 扩展R通道
uint16x8t glo = vmovlu8(vgetlowu8(rgbvec.val[1])); // 扩展G通道
uint16x8t blo = vmovlu8(vgetlowu8(rgbvec.val[2])); // 扩展B通道
// 灰度公式:0.299*R + 0.587*G + 0.114*B
uint16x8t graylo = vaddqu16(vmulqnu16(rlo, 77),
vaddqu16(vmulqnu16(glo, 150),
vmulqnu16(blo, 29)));
graylo = vshrqnu16(graylo, 8); // 右移8位近似除法
vst1qu8(gray + i, vmovnu16(gray_lo)); // 存储结果
}
}`
此实现通过一次处理16像素,显著提升了吞吐量。实际应用中需结合具体硬件调整并行度。
四、技术服务支持
为保障NEON开发的顺利实施,技术服务应涵盖以下方面:
- 架构咨询:根据目标平台(如Cortex-A53/A76)提供NEON兼容性评估和性能预期分析。
- 代码移植:协助将现有标量代码迁移至NEON优化版本,确保功能正确性和跨平台兼容性。
- 性能 profiling:使用工具链进行深度性能分析,识别瓶颈并优化关键代码段。
- 测试验证:通过单元测试和基准测试确保优化后代码的准确性与稳定性,避免数值精度损失。
五、未来展望
随着ARM架构在服务器、边缘计算等领域的普及,NEON技术将与AI加速器(如NPU)协同工作,形成异构计算解决方案。开发者需持续关注ARMv9等新架构的SVE2指令集,以应对更复杂的并行化需求。
NEON开发是一项结合算法设计、硬件特性和工程实践的综合性工作。通过系统性的设计实现方案,结合专业的技术服务,可充分发挥ARM处理器的潜力,为应用带来显著的性能提升。
如若转载,请注明出处:http://www.guangxi-boditech-db.com/product/14.html
更新时间:2025-11-29 12:36:53